Motion Capture
Triangulation
Introduction
Optical Motion Capture works on the simple principle of inverse projection and triangulation. The complexities (especially in systems like Vicon) come extensions of these basic principles, but in general the basic idea is still the same.
Inverse Projection
Inverse Projection takes the inverse route followed by perspective projection in 3D graphics (whereby a 3D scene is presented as a 2D image using a view frustum and the loss of z-depth). In this case, we have a 2D image and we need to determine the 3D space that the camera is viewing. As with perspective projection we need to have knowledge of the frustum (along with a few other correctional elements), in this way we are basically assigning a line from a pixel on the 2D image as being a line from that pixel back through the lens and into the 3D space (we can see this as a side view in Figure 1a).
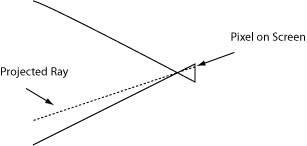
Triangulation
Therefore, anything that intersects that line will be represented in that pixel, so in general we have an idea of where in space along the X, Y coordinate system of the camera's 3D space the object the pixel is representing is; but we do not know anything about the Z-position (because we don't have that information). The only thing we do know about the Z-direction is that if we can see it on the 2D image, it must not be occluded.
In order to determine the Z-position of that object's position, we need to use another camera (which is obviously not in the same position as the original camera). In this case, we follow the same procedure for the second camera and determine which pixel produces a line that intersects our original line. If we know the position of the two cameras (even only relatively) then we can use this information to determine the Z-position of the object.
The Third Camera
In general, having 2 cameras should be sufficient for triangulation, however we are essentially determining the position of a marker from the intersection of two lines; problems occur when a another marker is occluding that intersection. In this case the two rays from the original two cameras will intersect, but it will create a false intersection. In this case a 3rd camera can help validate the position of an intersection (as it will not be occluded by the same marker).